 Horizontal Logo CMYK Full Colour.png)
What are some data considerations when framing an AI project?
Contents
What are some data considerations when framing an AI project?#
Contributor: Tan Kwan Chet, Lead AI Technical Consultant
Key Areas in Data#
Quote from Andrew Ng#
AI systems need both code and data, and “all that progress in algorithms means it’s actually time to spend more time on the data,” Ng said at the recent EmTech Digital conference hosted by MIT Technology Review.
Data Centricity#
With the rise of Data-Centric AI (DCAI) since 2021, there is a switch in focus from code that builds the model to the data that model is trained on. The shift arises because improving the quality of the data could help model to perform better, and in a fairer and more robust manner, than simply improving the code alone.
4 Key Data Questions#
Having understood the business challenge and AI problem at hand, this is where you need to delve into understanding the data the sponsor will be providing. You need to assess if there are risks/uncertainties posed within the data collected and annotated for solving the AI problem. Because a good AI model not only relies on algorithms but also quality data.
In practice, there are many considerations and checks for data quality. In this article, we focus on 4 key questions that are highly relevant at the pre-project phase to ensure that the AI problem is feasible and well-scoped. Note that while this is written with a supervised learning approach in mind, most of the considerations are also applicable to other learning approaches.
1. Is the target clearly defined and labels available?#
Frequently, sponsor may not be able to articulate the target variable of interest. This is where the translation of the business problem in this chapter becomes important. This target variable must be related to a business outcome (e.g. reducing employee’s repetitive tasks, prioritising patients for treatment based on mortality rate) that the sponsor wants to achieve.
Based on the translated AI task, this is where you ascertain whether the sponsor has a clear definition for the class/value/object/entity/text etc that is to be inferred. This determines whether quality labels can be defined.
If the target is of classification nature, it will be ideal to observe the current label proportion (e.g. binary label: “yes”, “no”) to ascertain if there is presence of label data imbalance. If the label data is highly imbalanced (e.g. 5% positive label and 95% negative label), an alternative would be to reframe the AI problem as an anomaly detection problem. More importantly, you would be keen to confirm if the label data corresponds to the definition of the target and the availability of the label data.
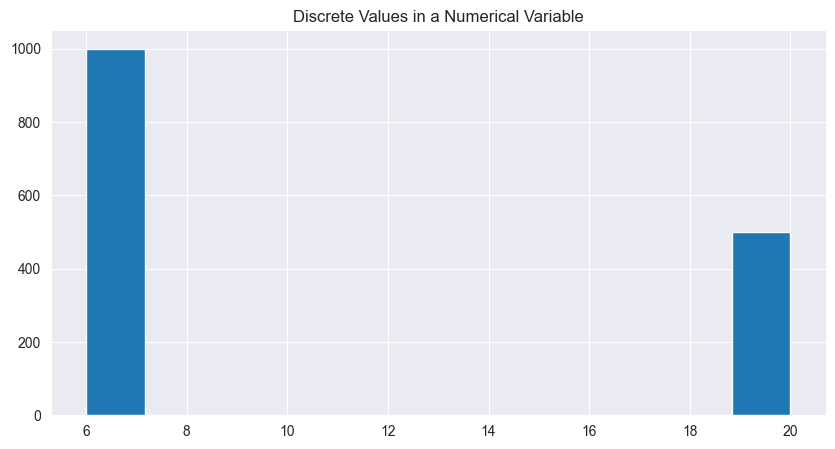
If the target belongs to a regression type, the question is more about ensuring the target variable is truly numeric/continuous. If upon checking you find that there is only a limited set of discrete values that the target variable can take on, it is better to reframe it as a classification problem. This is a possible scenario in businesses that rely on domain experts to run product experiments by testing different combinations of inputs with varying levels.
2. Does the data include features that can predict the target?#
An ideal way to estimate if the relevant features are present would be to ask the sponsor the following questions based on a priori domain knowledge:
If a human were to perform the task, what information would the person rely on to make the prediction?
Is this information available for training the model and during inference?
There should be adequate signal and variance within the relevant features. Signal refers to the presence of sufficient information relevant to predicting the target. Variance refers to having sufficient range and diversity of data.
This can be checked via a small, representative sample dataset from the sponsor.
for CV and NLP problems, using a pretrained model to run inference on sample data is a great way to assess the ‘information-ness’. Sometimes, you can also ‘eyeball’ the data, since for images and text, WYSIWYG!
for tabular problems, you can create a plot of mutual information/correlation between features and the target variable. A simple example is shown below for numeric features.
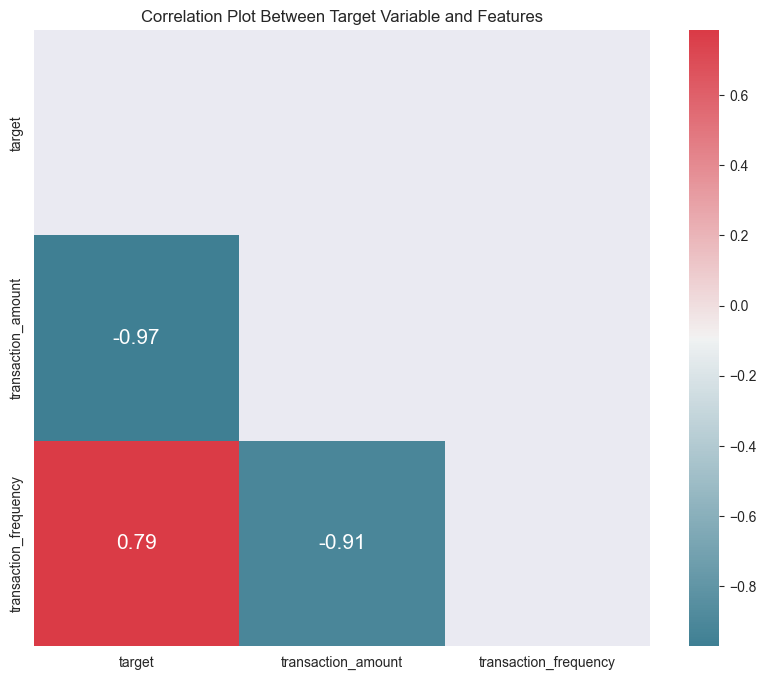
At times, you will face a situation in which sponsor claims that their domain knowledge is accurate in determining the predictive features while our exploratory data analysis (EDA) lends limited support for it. You could attempt some denoising techniques (e.g. outlier removal, averaging/binning) and check if the correlation improves. If it does not improve, this might be due to some confounding effect of a third feature that may influence the relationship between target and feature of interest.
3. Is the data at the correct granularity?#
It is critical to ensure that the training data and production data share the same level of granularity (e.g. hourly, daily, weekly, monthly or yearly) as what your sponsor expects in prediction. So if the sponsor expects the prediction on an hourly basis and the sponsor collects the data daily, then it will not be possible to build such an AI model to produce a granular prediction based on aggregated data. It is also worthy to note that if expected prediction is at a higher or similar granularity as the training or production data, then it is possible to build an AI model.
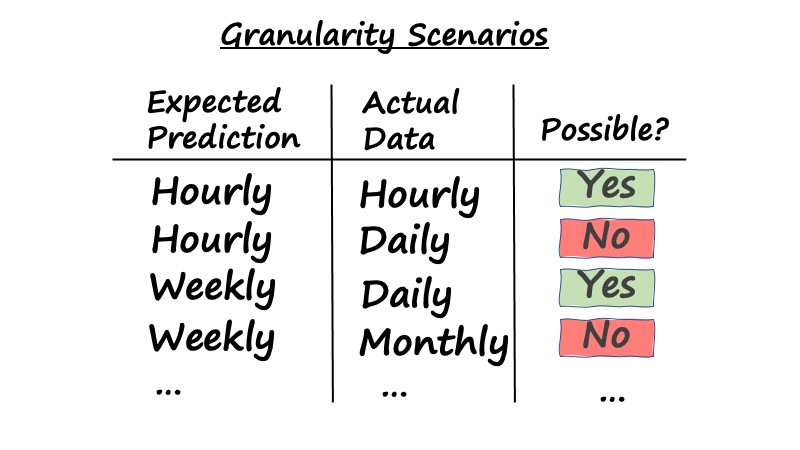
Besides matching granularity between training and production data, understanding the correct granularity allows you to estimate the volume of data available for training. For example, if the goal is to aggregate a sensor’s readings from seconds to hours for prediction, because the per-second readings contain mostly noise, then having “86,400 data points” may sound like a large dataset, but in actual fact, it is insufficient as there are only 24 hourly aggregates for you to work with.
4. Is the training data representative of the production data?#
It is critical that training data is representative of the production data to ensure the trained model will be fair and robust:
Avoid unintended bias. If the model is trained on training data that is dominated by a specific label (i.e. majority label), then it is very likely that the model is robust in predicting a majority label while it will unlikely predict a minority label.
Improve robustness and generalisability. The distribution of training data will be what the model will learn from. Assuming that the distribution between training and production data is highly similar, this would mean that the trained model is able to generalise and make robust predictions in varying contexts that are often present in production data. It also means the model is less prone to immediately drift the moment it is applied in production.
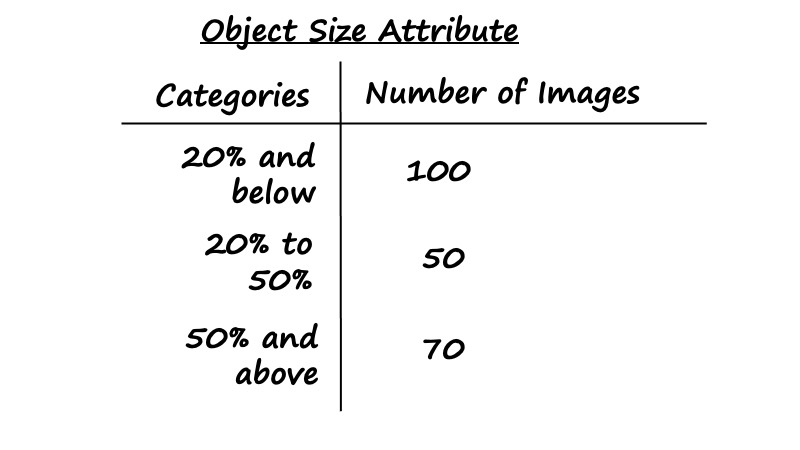
So how we check for representativeness? To do so, you would first need to discuss and identify a few key attributes that capture the defining characteristics of the data. Here is an example for a salient object detection problem, where ‘size of objects’ and ‘whether there are multiple objects’ are 2 attributes. For problems that involve human subjects like customers and patients, defining characteristics could include key demographics like age, gender and ethnicity.
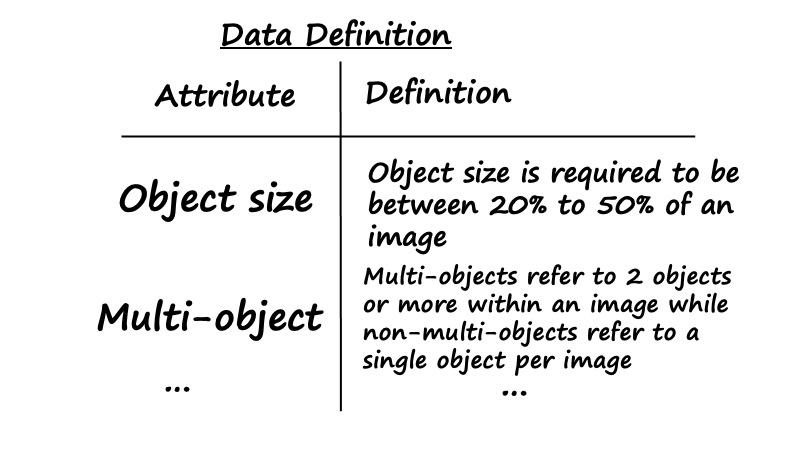
Once you are able to define these, you could request the sponsor to estimate the proportion of their production data broken down by different attributes. For example, below is a breakdown of the distribution of object size for the salient object detection dataset. The goal is then to ensure that the training data matches this production distribution:
Using these 4 key questions will allow you to have a gauge of the quality of the data for building the model. This is an important starting point for building a model that has good predictive power, and it is also fair and robust.