 Horizontal Logo CMYK Full Colour.png)
What are some ways to do EDA for CV tasks?
Contents
What are some ways to do EDA for CV tasks?#
Contributor: Calvin Neo, AI Engineer
The purpose of this article is to guide new AI Engineers on performing Exploratory Data Analysis of Computer Vision tasks in a systematic manner. It assumes a basic understanding of image format, and how bounding boxes and masks are drawn.
Image EDA#
Basic Image Analysis#
The basic image analysis considers the broad characteristics of the images that have been obtained.
The guiding questions are as such:
What is the number of images provided? Is this the number of images promised to be delivered for experiments?
What is the format of images eg JPG/PNG/JPEG? If there are multiple formats given, what are the counts for each image format?
What are the image sizes/resolution (eg 1080x960)? If there are multiple dimensions, what are the counts for each dimension?
How similar are the images to each other? You can do an EDA to check on this by performing image hashing to discover groups which are similar to each other. This also helps to uncover whether some of the images might have been curated from a continuous video stream of a scene that is changing very slowly - in such a case, these images may be near-duplicates.
Colour Intensity of Images#
The colour intensity of images can be explored by either mean or mode of the channel values of each image. The goal for analysing annotations’ colour channels is to understand what the dominant colours are. For example, images in forest settings may have more green, and images along water bodies are expected to be blue-dominated. This also ties in with annotations, where if the annotated objects are similar in colour values, the model would need to rely on feature other than colours such as edges.
Brightness of Images#
Brightness values are closely related to colour intensity. If the colour intensity for all channels are higher, then the images may appear to be brighter than normal and vice versa. It is thus the job of the AI Engineer to explore the data to ensure the brightness values of the images are of the normal range. Otherwise, they would need to scale up or down the brightness levels to ensure that the images for training are consistent.
Contrast of Images#
Contrast is the pixel to pixel difference in channel values. For example, a green frog in Bukit Timah Nature Reserve would be said to have low contrast. This makes edge detection more important for the model.The onus is thus on the AI Engineer to explore the images to ensure the contrast levels are of the normal range. Otherwise, they would need to employ contrast adjustment techniques to ensure contrast values are normalised.
Image Similarity#
PCA or ISOMAP per channel can be performed on the images to see how the images are related to each other.
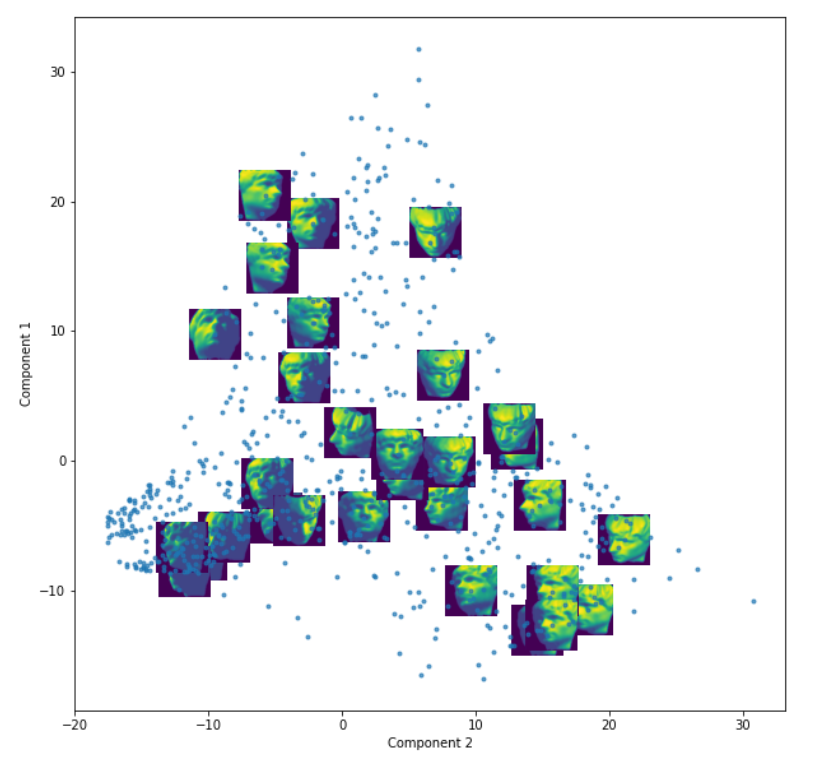
Annotations (Basic Overview)#
Bounding Boxes Formats#
COCO - [x_min, y_min, width, height]
YOLO - [x_center, y_center, width, height]
Pascal VOC - [x_min, y_min, x_max, y_max]
For example, if the given format is in Pascal VOC, and the model requires it in YOLO format, we would need to convert the annotations to YOLO format for training.
An example for during inference: Read images using CV2, run YOLOv3 model, convert and return in the desired format according to what is required to be delivered.
Masks Format#
Masks annotations gives the pixel-wise positions of the mask.
Masks are provided in an array of x-y pairs. It will typically be:
masks_per_instance = [x_1, y_1, x_2, y_2, ... x_n, y_n]
Masks may also come in the form of PNG files, where the PNG’s image size would correspond to the original image size.
Annotations EDA#
Basic Annotations Analysis#
The basic annotations analysis attempts to find characteristics of the annotation such as number (and proportion) of classes as well as the values of the bounding boxes/ masks.
This is useful because it helps determine what type of metrics should be used, how the data (images) should be split, and what parameters could be tuned. For metrics, the usual case for this is error analysis of model performance on bounding box sizes. For example, if the bboxes/masks are mostly large objects among all the images, assuming images are sufficiently clear, it is clear that the model will do well. However, if the annotations are small, then the model will inevitably struggle. Hence, the AI Engineer will pay attention to certain metrics more, such as mAP with Area=Large.
The data split refers to how one might partition the data for training/validating/testing the model. Generally, all sets would need similar proportions of the bbox size (small/medium/large) and class distribution. In the ideal scenario, these proportions are easy to split at random, but it is extremely rare. Thus, by performing EDA on the annotations, the Engineer will have a better idea on how the data split can be done.
Tuning parameters refers to configuring parts of model training/inference that could be useful for better performance. An example of this is anchor box size(s). By default, the anchor box sizes in the models were set to be tuned to the dataset that they were benchmarked against, for example MS COCO Dataset. However, the bbox/mask of real data that is received would not fit nicely to these anchor box sizes. Hence, by understanding a particular range of typical bbox/mark sizes, the anchor box sizes can be tuned to accomodate the range. This has been observed to be beneficial to model training and inference performance.
With these considerations in mind, these are some guiding questions when performing EDA on annotations:
How many instances of each classes are there?
Bounding Box - what is width and height distribution overall and per class?
Bounding Box - what is the overall size (W*H) overall and per class?
Bounding Box - What are the top few Width/Height combination? This can be found using clustering methods.
Segmentation - what is distribution of the mask pixel counts overall and per class?

Colours of Annotations#
As with images, the annotations have 1 or more channels per pixel, with the most popular format being Red, Green and Blue (RGB). The utility for this mainly lets the researchers know if the model would be better served trying to use certain channels when making inference.
Average Intensity per channel#
To explore this for all classes, we can firstly average the colour intensity of the annotation’s pixels per channel.
Secondly, countplot of the average colour intensity values could be generated. The image below shows the counts of each annotation with the average values of the red channels separated by classes. In this case, there are three classes, with one of the class having very spread out red channel intensity, and the other two classes having colour intensity being normally distributed.
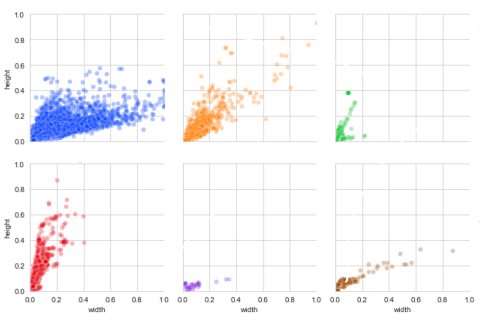
Example of a Height-Width comparison among bboxes separated by class.
Mode Intensity per channel#
Besides averaging the intensity per annotation, the highest occurring value (mode) of the intensity of the annotation can also be used to analyse the colour of the annotation.

There are many other ways to visualise this. The main goal is to check on the colour distribution among the annotations.
Annotations Random Sample Checks#
Bounding Box and Mask Random Sample Checks#
Bounding Boxes Random Sample Check refers to performing a check by sampling images and analysing their annotations. These try to account to account for human error that very often occurs.
Are the bboxes/masks drawn tight enough?
Were the bboxes/masks drawn accurately?
Are the objects being occluded? In other words, were parts of the object blocked by another object? In general, if the object of interest is being occluded, its annotation should still be drawn such that it includes the occluded portion.
Are the objects truncated? In other words, were parts of the objects “spilling” out of the image?
For occlusion and truncation, it is recommended to include “occlusion” and “truncation” in the metadata of the annotation.
Conclusion#
This was a short survey of some of the areas in which the AI Engineer can begin in exploratory data analysis for images as well as their annotations. This is by no means exhaustive, and the AI Engineer should explore further methods for EDA in this space.
References#
Perceptual Hashing - https://www.phash.org/
VOC annotation guide - http://host.robots.ox.ac.uk/pascal/VOC/voc2011/guidelines.html
The Scientist and Engineer’s Guide to Digital Signal Processing - https://www.dspguide.com/ch23/5.htm
Further EDA readings#
Histogram -
https://homepages.inf.ed.ac.uk/rbf/HIPR2/histgram.htm http://web.cs.wpi.edu/~emmanuel/courses/cs545/S14/slides/lecture02.pdf https://www.allaboutcircuits.com/technical-articles/image-histogram-characteristics-machine-learning-image-processing/
Anchor Boxes - https://d2l.ai/chapter_computer-vision/anchor.html
Other Data Exploration Ideas -
https://neptune.ai/blog/data-exploration-for-image-segmentation-and-object-detection